
SCD-2 considered harmful! Part 2
Date stamp your data!


Not everything you learned in college about data warehousing still applies in 2025.
This is part 2 of Sahar’s unlearning data warehousing concepts series. (make sure to read part 1 first if you haven’t “The Data Setup No One Ever Taught You” series)
Sahar and I learned a lot during out time working in core growth together at Facebook working in friending and notifications.
Let’s talk about the pain of unlearning and then let’s get to the magic.
Imagine you’re an analyst at a social media company. The retention team asks: “For users who now have 1000+ followers but had under 200 three months ago – what device were they primarily using back then? And of the posts they viewed during that growth period, how many were from accounts that were mutuals at the time?”
You need to join user data (follower counts then and now), device data (primary device then and now), relationships (who was a mutual then vs now), and post views – all as of 3 months ago.
With most data warehouse setups, this query is somewhere between “nightmare” and “impossible.”
You’re dealing with state, not actions. State in the past, across multiple tables. There’s a word for this problem – slowly changing dimensions. Whole chapters of textbooks deal with various approaches. You could try logs (if you logged the right stuff). You could try slowly changing dimensions with `valid_from/valid_to` dates. You could try separate history tables. All of these approaches are painful, error-prone, and make backfilling a living hell.
There’s a better way. Through the magic of ✨datestamps✨ and idempotent pipelines, this query becomes straightforward. And backfills? They become a button you push.
Part 1 fixed weird columns, janky tables, and trusting your SQL. Part 3 will cover scaling your team and warehouse. But now – now we fix: backfills, 3am alerts, time complexity, data recovery, and historical queries.1
The old way was a mess
Here’s what most teams do when they start out:
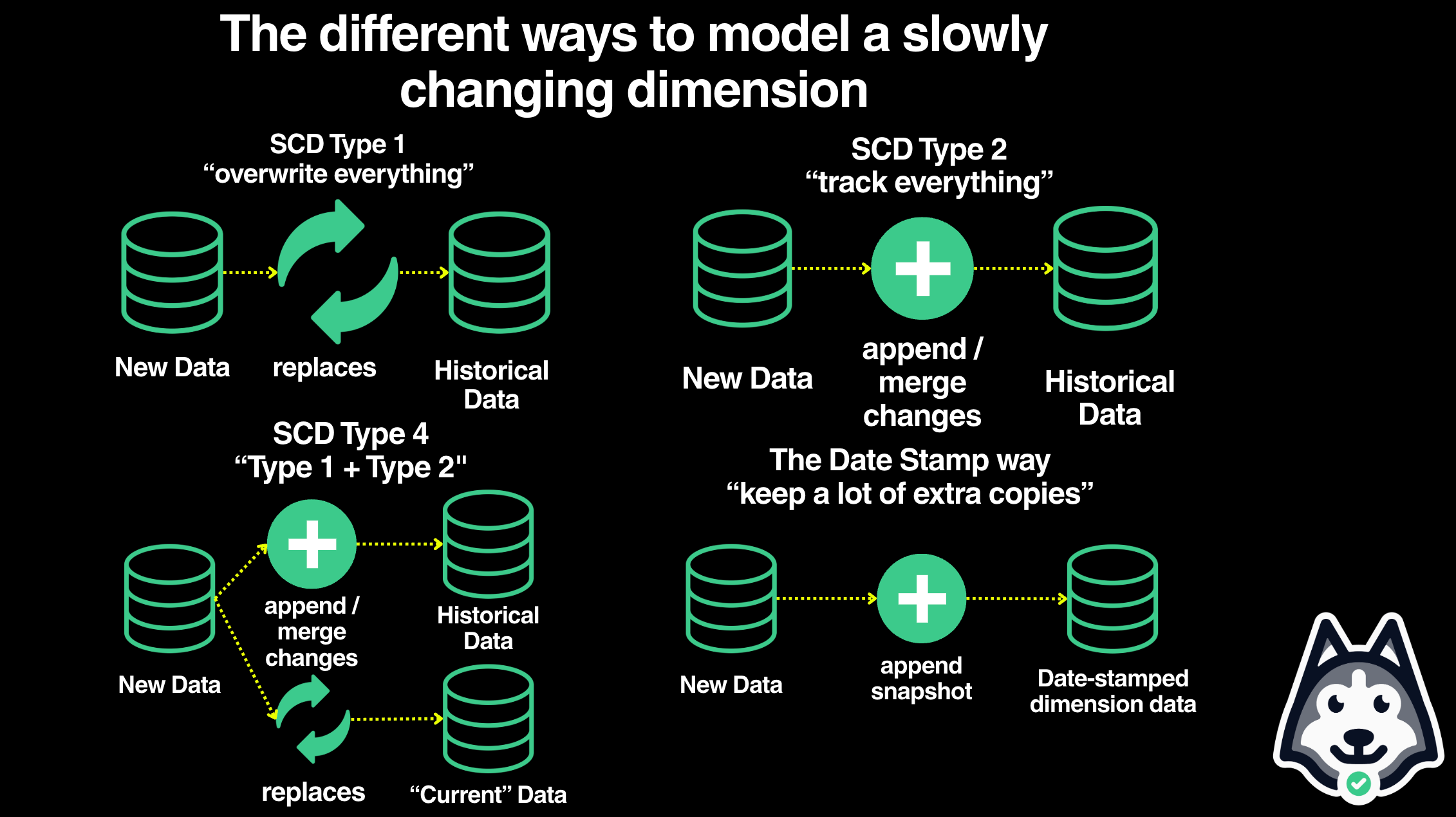
Option 1: Overwrite everything daily
Your pipeline runs every night, updates dim_users with today’s snapshot, overwrites yesterday’s data. Simple! Until six months later when someone asks “how many followers did users have in March?” and you realize: that data is gone. You have no history. You can’t answer the question. Oops.
(Jargon alert – Apparently this is SCD Type-1 ¯\_(ツ)_/¯ )
Option 2: Try to track history manually
Okay, you think, let’s be smarter. Add an updated_at column. Or maybe valid_from and valid_to dates, with an is_current flag. When a user’s follower count changes, don’t update their row – instead, mark the old row as outdated and insert a new one.
(Jargon alert – This is SCD Type-2. Booo)
This is better! You have history. But now:
Your pipelines need custom logic to “close out” old rows before inserting new ones
If you mess up the
valid_todates, you get gaps or overlaps in historyBackfilling becomes a nightmare – you can’t just rerun a pipeline, you need to carefully update dates without breaking everything downstream
Querying becomes a nightmare. To get user data “as of 3 months ago”, you need:
SELECT * FROM dim_users WHERE user_id = 123 AND valid_from <= ‘2024-10-01’ AND (valid_to > ‘2024-10-01’ OR valid_to IS NULL)
Now imagine joining MULTIPLE historical tables (users, devices, relationships). Every join needs that BETWEEN logic. Miss one and your results are silently wrong. Get the date math slightly off and you’re joining snapshots from different points in time. Good luck debugging that.
Option 3: Separate current and history tables
Some teams maintain dim_users (current snapshot) and dim_users_history (everything else). Now you’ve got two sources of truth to keep in sync. Analysts need to remember which table to query. Any analysis spanning current and historical data requires stitching across tables with UNION ALL. It’s a mess.
And, depending on how the dim_users_history table works – it won’t solve any of the problems you’d have in option 2!
All of these approaches share a problem: they’re trying to be clever about storage. They made sense when disk was expensive. They don’t anymore.
(Jargon alert – This is SCD Type-4. Note that I didn’t know this when I started writing this blog post because it’s useless, boring, outdated jargon. Ignore it.)
Sponsorship
If you want to learn more about data modeling and data architecture in detail, you can use code SCDSUCKS by November 14th to get 35% off the DataExpert.io Snowflake + dbt boot camp

The new way: Just append everything
You solve it with date stamps. You solve it with “functional data engineering”.
What you really want is a sort of table that tracks state – a dimension table –, but where you can access a version that tracks information about the world today, and another version that tracks information about the world in the past.
Maxime Beauchemin wrote the seminal public work on the idea here. But, honestly, I think the concept can be explained more plainly and directly. So here we are.
The thinking goes like this:
We’re getting new data all the time.
Let’s simplify it and say – we get new data every day. We copy over snapshots from our production database each evening.
There are complex, convoluted ways to keep track of what data is new and useful, and what data is a duplicate of yesterday.
But wait. Storage is cheap. Compute is cheap. Pipelines can run jobs for us while we sleep.
It’s annoying to have a table with the data we need as of right now, and either some specialized columns or tables to track history..
Instead, what if we just kept adding data to existing tables? Add a column for “date this information was true” to keep track.

Here’s what it looks like in practice. Instead of overwriting your dimension tables every day, you append to them:
dim_users
┌─────────┬───────────┬────────────┐
│ user_id │ followers │ ds │
├─────────┼───────────┼────────────┤
│ 123 │ 150 │ 2024-10-01 │
│ 123 │ 180 │ 2024-10-02 │
│ 123 │ ... │ ... │
│ 123 │ 1200 │ 2025-01-16 │
└─────────┴───────────┴────────────┘
dim_devices
┌─────────┬─────────┬────────────┐
│ user_id │ device │ ds │
├─────────┼─────────┼────────────┤
│ 123 │ mobile │ 2024-10-01 │
│ 123 │ mobile │ 2024-10-02 │
│ 123 │ ... │ ... │
│ 123 │ desktop │ 2025-01-16 │
└─────────┴─────────┴────────────┘
dim_relationships:
┌─────────┬───────────┬───────────┬────────────┐
│ user_id │ friend_id │ is_mutual │ ds │
├─────────┼───────────┼───────────┼────────────┤
│ 123 │ 789 │ true │ 2024-10-01 │
│ 123 │ 789 │ true │ 2024-10-02 │
│ ... │ ... │ ... │ ... │
│ 123 │ 789 │ false │ 2025-01-16 │ ← changed
└─────────┴───────────┴───────────┴────────────┘
fct_post_views:
┌─────────┬───────────┬───────────┬────────────┐
│ post_id │ viewer_id │ poster_id │ ds │
├─────────┼───────────┼───────────┼────────────┤
│ 5001 │ 123 │ 789 │ 2024-10-01 │
│ 5002 │ 123 │ 456 │ 2024-10-01 │
│ 5003 │ 123 │ 789 │ 2024-10-05 │
│ ... │ ... │ ... │ ... │
│ 9999 │ 123 │ 789 │ 2025-01-15 │
└─────────┴───────────┴───────────┴────────────┘Now that impossible retention query becomes straightforward. No BETWEEN clauses, no valid_from/valid_to logic – just filter each table to the date you want:
-- For fast-growing users, what device did they use back then?
WITH
today_users as (SELECT user_id, followers as today_followers
FROM dim_users WHERE ds = ‘2025-01-16’ AND followers >= 1000),
past_users as (SELECT user_id, followers as past_followers
FROM dim_users WHERE ds = ‘2024-10-01’ AND followers < 200),
past_device as (SELECT user_id, device
FROM dim_devices WHERE ds = ‘2024-10-01’),
user_device as (
SELECT tu.user_id, today_followers, past_followers, pd.device
FROM past_users pu
JOIN today_users tu ON pu.user_id = tu.user_id
JOIN past_device pd ON tu.user_id = pd.user_id),
views as (
SELECT post_id, viewer_id, poster_id, ds
FROM fct_post_views
WHERE ds BETWEEN ‘2024-10-01’ AND ‘2025-01-16’)
SELECT
ud.user_id,
ud.device as device_during_growth,
COUNT(DISTINCT views.post_id) as posts_from_mutuals
FROM user_device ud
LEFT JOIN views
ON ud.user_id = views.viewer_id
LEFT JOIN dim_relationships past_rels
ON views.viewer_id = past_rels.user_id
AND views.poster_id = past_rels.friend_id
AND views.ds = past_rels.ds -- mutual status AS OF view date
AND past_rels.is_mutual = true
GROUP BY 1, 2Is this query complex? Sure.2 But the complexity is in the business logic (what you’re trying to measure), not in fighting with valid_from/valid_to dates. Each query just filters to ds = {the date I want}. That’s it.
The idea is that you’re not overwriting existing tables. You are appending. 3
Sidebar: Common Table Expressions
If I had a SECOND “one weird trick” for data engineering, CTEs would be it. CTEs are just fucking fantastic. With liberal use of common table expressions (the
WITHclause you saw in the retention query above), you can treat subqueries like variables – and then manipulating data feels more like code. Make sure your query engine (like Presto/Trino) flattens them for free – but if it does: wowee! SQL just got dirt simple. (a free one hour course on CTEs here)
When you grab data into your warehouse4, append a special column. That column is usually called “ds” – probably short for datestamp. You want something small and unobtrusive. (Notice that “date” would be a bad name – because you’d confuse people between this (date of ingestion of data) and the more obvious sort of date – date the action happened.) For snapshots, copy over the entire data of the snapshot, and have your “ds” column be <today’s date>. For logs, you can just grab the logs since yesterday, and set the ds column to <today’s date>.
Sidebar: Date stamps vs Date partitions
I’ll mostly say “date stamps” in this piece – the concept of marking each row with when that data was valid/ingested.“Date partitions” is how most warehouse tools *implement* date stamps. A partition is how your warehouse physically organizes data. Think of it like: all rows with
ds=2025-01-15get grouped together in one chunk,ds=2025-01-16in another chunk, and so on. (In older systems, each partition was literally a separate folder. Modern cloud warehouses abstract this, but the concept remains.)Why does this matter? When you query `
WHERE ds=’2025-01-15`, your warehouse only scans that one partition instead of the entire table. This makes queries faster and cheaper (especially in cloud warehouses where you pay per data scanned).People use the terms interchangeably. The important thing is the concept: tables with a date column that lets you query any point in history.
Every table emanating from your input tables should add a filter (WHERE ds={today}), and similarly append the data to the table (WHERE ds={today}). (Except special circumstances where a pipeline might want to look into the past).
That’s it! Now your naive setup (overwriting everything every day) has only changed a bit (append everything each day, and keep track of what you appended when) – but everything has become so much nicer.
This is huge
This has two major implications:
First, many types of analysis become much easier. Want to know about the state of the world yesterday? Filter with WHERE ds = {yesterday}. Need data from a month ago? Filter with WHERE ds = {a month ago}. You can even mix and match – comparing today’s data with historical data, all within simple queries.
Second, data engineering becomes both easier and much less error prone. You can rerun jobs, create tables with historical data, and fix bugs in the past. Your pipeline will produce consistent, fast, reliable results consistently
What “functional” actually means
(Aka “I don’t know what idempotent means and at this point I’m afraid to ask”)
So, in Maxime’s article (link) there’s all this talk about “functional data engineering”. What does that even mean? Let’s discuss.
First, we’re borrowing an idea from traditional programming. “Functional programs” (or functions) meet certain conditions:
If you give it the same input, you get the same output. Every time.
State doesn’t change. Your inputs won’t change, hidden variables won’t change. It’s clean. (AKA “no side effects”)
Okay, so what does that mean for pipelines? Functional pipelines:
Given the same input, will give the same output
Don’t use (or rely on) magic secret variables
This is what people mean when they say “idempotent” pipelines or “reproducible” data.
And here’s how to implement it: datestamps.
Your rawest/most upstream data should never be deleted – just keep appending with datestamps
Pipelines work the same in backfill mode vs normal daily runs
If you find bugs, fix the pipeline and rerun – the corrected data overwrites the bad data
Time travel is built in – just filter to any ds you need
Datestamps also give you the nice side-effect of having it be very clear how fresh the data you’re looking at is. If the latest datestamp on your table is from a week ago -- it’s instantly understandable not only what’s wrong, but also you have hints about why.
Sidebar – what this looks like in practice:
Your SQL will look something like:WHERE ds=’{{ ds }}’(Airflow’s templating syntax)orWHERE ds=@run_date(parameter binding).Your orchestrator injects the date - whether it’s today’s scheduled run or a backfill from three months ago. Same SQL, different parameter. That’s the whole trick.
Backfilling is now easy, simple, magical
Remember that retention query? Now imagine you built that analysis pipeline three months ago, but you just discovered a bug in your dim_relationships table. The is_mutual flag was wrong for two weeks in November. You fixed the bug going forward, but now all your retention metrics from that period are wrong.
With the old SCD Type-2 approach, you’re in hell:
You can’t just “rerun November.” Because each day’s pipeline depended on the previous day’s state. Day 15 updated rows from Day 14, which updated rows from Day 13, and so on. To fix November 15th, you’d need to:
Rerun November 1st (building from October 31st’s state)
Wait for it to finish
Rerun November 2nd (building from your new November 1st)
Wait for it to finish
Rerun November 3rd...
...keep going for 30 days, sequentially, one at a time
And this is assuming nothing breaks along the way. If Day 18 fails? Start over. Need to fix December too? Add another 31 sequential runs.

In Airflow terms, this is what depends_on_past=True does to you. Each day is blocked until the previous day completes. Backfilling becomes painfully slow. But that’s by no means the worst part.
You can’t just hit “backfill” and walk away. Your normal daily pipeline logic doesn’t work for backfills. Why? Because SCD Type-2 requires you to:
Close out existing rows (set their
valid_todate)Insert new rows (with new
valid_fromdates)Update
is_currentflagsHandle the case where a row changed multiple times during your backfill period
Your daily pipeline probably has logic like:
-- Daily SCD Type-2 pipeline (simplified)
-- Step 1: Close out changed rows
UPDATE dim_users
SET valid_to = CURRENT_DATE - 1, is_current = false
WHERE user_id IN (
SELECT user_id FROM users_source_today
WHERE <something changed>
)
AND is_current = true;
-- Step 2: Insert new versions
INSERT INTO dim_users (user_id, followers, valid_from, valid_to, is_current)
SELECT user_id, followers, CURRENT_DATE, NULL, true
FROM users_source_today;This works fine when you’re processing “today.” But for a backfill? You need different SQL:
You need to carefully reconstruct valid_from/valid_to for historical dates
And handle the fact that a user might have changed multiple times during your backfill window
This gets messy fast.
You’re essentially rewriting your pipeline. (WHY?)
So now you’re not just waiting 30 sequential days - you’re maintaining two separate codebases: one for daily runs, one for backfills. And every time you change your daily logic, you need to update your backfill logic to match. More code to write, more code to test, more places for bugs to hide. It’s completely useless and unnecessary.
Sidenote – even worse, if you’re outside your retention window (say, the source data from 90 days ago has been deleted), you can’t backfill at all. You’d need to completely rebuild the entire table from scratch, from whatever historical snapshots you still have. Which probably means... datestamped snapshots anyway. Womp womp.
With datestamps, backfilling is trivial:
Your pipeline for any given day just needs:
Input tables filtered to
ds=’2024-11-15’(or whatever day you’re processing)Write output to
ds=’2024-11-15’
That’s it. November 15th doesn’t need November 14th. It just needs the snapshot from November 15th.
So to fix your broken November data:
# In Airflow (or whatever orchestrator)
> airflow dags backfill my_retention_pipeline \--start-date 2024-11-01 \--end-date 2024-11-30What happens behind the scenes?
All 30 days kick off in parallel (up to your concurrency limits)
Each day independently reads from its ds partition
Each day independently writes to its ds partition
No coordination needed between days
The whole month finishes in the time it takes to run one day
The exact same SQL that runs daily also handles backfills - no special logic, no custom code
This changes everything:
No more custom SQL for backfills - It’s just a button you push. Your orchestrator handles it. The same pipeline code that runs daily also handles backfills. No special logic needed.
New tables get history for free - Created a new dim_users_enriched table today but want to populate it with the last year of data? Just backfill 365 days. Since your input tables have datestamps, the data is sitting there waiting.
Bugs in old data become fixable - Fix your pipeline logic, backfill the affected date range, done. The old (wrong) data gets overwritten with the new (correct) data for those specific partitions. Everything downstream can reprocess automatically.
Upstream changes cascade easily - Fixed a bug in dim_users? All downstream tables that depend on it can backfill the affected dates in parallel. The whole warehouse stays in sync.
This is possible because your pipelines are idempotent. Run them once, run them a thousand times - given the same input date, you get the same output. No hidden state, no “current” vs “historical” logic, no manual date math.
One pattern to avoid: Tasks that depend on the previous day’s partition of their own table. If computing today’s dim_users requires yesterday’s dim_users, you’ve created a chain - backfilling 90 days means 90 sequential runs that can’t be parallelized. This is sometimes necessary for cumulative metrics, but most dimension tables don’t need it - just recompute from raw sources each day.
For most datestamped pipelines, depends_on_past should be False. Each day is independent - the only dependency is “does the upstream data exist for this ds?”
Welcome to the magic of easy DE work
We started this article staring at the prospect of valid_from/valid_to logic, sequential backfills that take days, and custom SQL for every backfill and cascading for every bugfix. Yuck. Ew!
Or maybe – worse – with no sense of history at all. No ability to ask “how did the world look like yesterday”, much less “3 months ago”. I’ve seen startups and presidential campaigns and 500 million dollar operations operate like this. 🙃
Now you know the secret. Now you have the magic. What mature companies have been doing all along: snapshot your data daily, append it with datestamps, and write idempotent pipelines on top.
That’s it. That’s the whole One Weird Trick. Add a ds column to every table. Filter on it. Write your pipelines to be independent of each other. Have every pipeline be ds-aware. Storage is cheap. Your time is expensive. Getting your data wrong is extra expensive.
What you get in return:
Backfills that run in parallel and finish in minutes instead of days
Backfills that are a button push instead of custom SQL mess.
Historical queries that are simple
WHERE ds=’2024-10-01’filters instead of date-range gymnasticsPipelines that are the same whether you’re processing today or reprocessing last year
A built-in time machine for your entire warehouse
Bugs that are fixable instead of permanent scars on your data
This is functional data engineering. Functional as in idempotent. And functional as in “it works”.
Your backfills are easy now. Your 3am alerts will be rarer. Time complexity is solved. Data recovery is trivial. Your job just became so much easier.
But we’re not done yet. Part 3 will tackle: how to scale your team and your warehouse. Parts 4 and 5 are gonna get me back on my “he who controls metrics controls the galaxy” soapbox.
For now, go add some datestamps. Your future self will thank you.
Hey, it’s Zach again. Sahar is currently open to work in NYC. Make sure to follow Sahar’s blog to understand growth and what comes next, both personally and for your business! And more at sahar.io
Except naming. That’s on you.
But actually much simpler due to my favorite SQL tool – Common Table Expressions!
Technically you’re appending if today’s ds is empty and replacing if there is data in today’s ds
Ideally daily. You might do logs hourly, but let’s ignore that for simplicity
One thing I forgot to make clear in the article is that --
1. If you partition your data, doing snapshots adds 0 latency
2. If you send partitions to cold storage after, say, 3 months, then your tables stay roughly the same size over time.
Date-stamped snapshots are solid for analytic state questions and fast backfills. No argument from me on that, but where this breaks down is human-edited operational data. Salesforce, NetSuite, HubSpot, finance apps. Human entered data... Those records flip after the fact, and auditors expect an immutable trail tied to who changed what and when.
If you need real auditability, capture changes first (CDC or event log). Then layer convenience: a “latest” view for analysts and, if needed, an SCD2 history table for business reporting. Snapshots alone are fine for product analytics; they’re not enough for regulated ops data.
So the choice isn’t “SCD2 vs datestamps.” It’s immutable facts at the base, with snapshots or SCD2 as views that match the model and the risk.
Your question might be but how does SCD2 fix this?
It “fails” only if your ingestion cadence or diff method is too coarse. Fix with CDC or higher-frequency diffs. SCD2 will happily store the extra versions.
Then SCD2 is the storage pattern and CDC is the microscope.