
Stopping Silent Failures for Meta's Fake Accounts Pipeline
Data Orchestration Challenges I Faced at Airbnb, Netflix & Facebook – Part IV

One of my final projects at Facebook was owning the data pipeline that tracked fake accounts. It may sound simple but, in reality, it was one of the most deceptively complex orchestration problems I’ve ever encountered and made worst by a hidden upstream design choice that prioritized speed of delivery over data consistency.
Fake accounts come and go. Some are flagged incorrectly, others are later verified, and many are caught by internal ML systems. The goal of our pipeline was to trace the inflows and outflows of fake accounts daily. That meant building a reliable dataset that could track:
Accounts unlabeled as fake (i.e. after submitting a valid ID)
Accounts relabeled as fake
Accounts flagged as fake for the first time
Accounts that remained fake
The pattern was very straightforward: a classic cumulative table design. But the way it was wired to upstream data, specifically how it “waited” for inputs, created a non-deterministic nightmare. For weeks, I chased what I thought was a bug in my code, only to discover that the real problem had been there from day one.
In this article, I’ll cover the following aspects:
Why relying on “latest” partition data broke everything
How upstream non-deterministic leads to silent data mismatches
The simple fix using explicit partition dates
The tradeoff between latency and reproducibility
Engineering lessons that go beyond code
If you want to learn more in depth about patterns like this, the DataExpert.io academy subscription has 200+ hours of content about system design, streaming pipelines, etc. The first 5 people can use code FAKE for 30% off!
If you enjoy this article, here are some more from my time in big tech:
How I achieved a 12x speed up on Facebook notification pipelines
How I used the “Psycho” pattern to detect threats at Netflix

Understanding Fake Account Flows
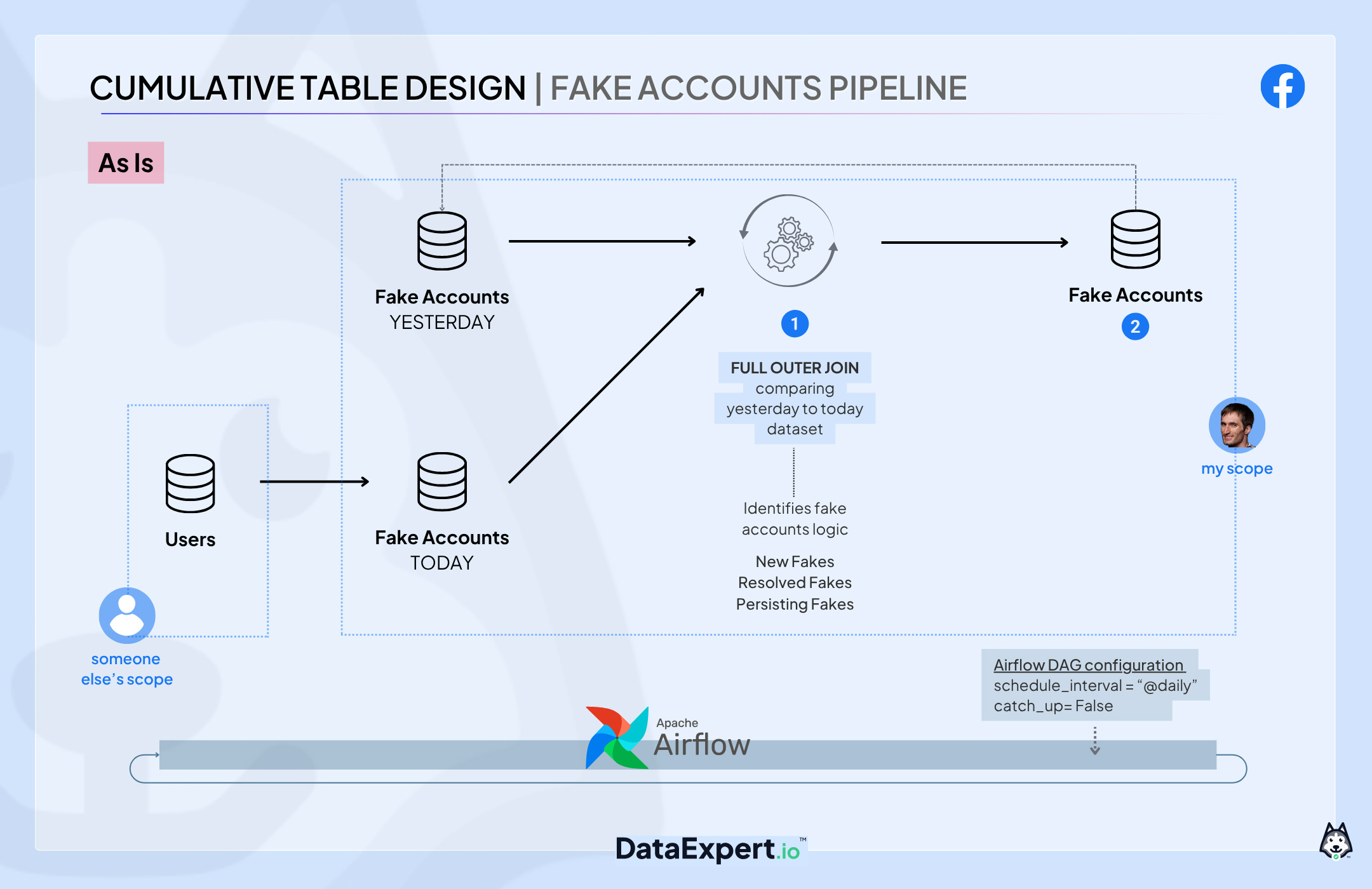
At a high level, the pipeline’s job was to compare today’s and yesterday’s fake account snapshots, determine who had entered or exited the fake state, and store those inflow/outflow transitions for downstream analytics.
This was a classic cumulative table design pattern, built in plain vanilla SQL and tracked four main fake states:
New fakes → New people who got labeled as fake
Resolved accounts → People who were labeled fake earlier than today and passed a challenge to remove the label
Persisting fakes → People who were labeled fake earlier than today and haven’t passed a challenge
Relabeled fakes → People who were labeled fake, passed a challenge, and then continued to do fake activity
Originally, it was set up like this:
Fake accounts pipeline waited on the “latest” partition of the users table
Then joined it with fake_accounts to compute transitions
The job ran daily and published results
-- Define struct and enum types
CREATE TYPE IF NOT EXISTS daily_detection_stats AS (
detection_date DATE,
login_attempts INTEGER,
friend_requests_sent INTEGER,
posts_created INTEGER,
flagged_reports INTEGER
);
CREATE TYPE IF NOT EXISTS fake_classification AS ENUM('new', 'resolved', 'persisting', 'relabeled');
-- Create cumulative table
CREATE TABLE IF NOT EXISTS fake_accounts
(
account_id TEXT,
country TEXT,
sign_up_method TEXT,
sign_up_date DATE,
daily_detection_stats daily_detection_stats[],
fake_classification fake_classification,
days_since_last_detected INTEGER,
current_detection_date DATE,
PRIMARY KEY (account_id, current_detection_date)
);
-- Dynamically pick the "latest" date
WITH latest_date AS (
SELECT MAX(detection_date) AS detection_date FROM account_daily_signals
),
yesterday AS (
SELECT *
FROM fake_accounts
WHERE current_detection_date = (SELECT detection_date - INTERVAL '1 day' FROM latest_date)
),
today AS (
SELECT * FROM account_daily_signals
WHERE detection_date = (SELECT detection_date FROM latest_date)
)
-- Non-idempotent insert
INSERT INTO fake_accounts
SELECT
COALESCE(t.account_id, y.account_id) AS account_id,
COALESCE(t.country, y.country) AS country,
COALESCE(t.sign_up_method, y.sign_up_method) AS sign_up_method,
COALESCE(t.sign_up_date, y.sign_up_date) AS sign_up_date,
CASE
WHEN y.daily_detection_stats IS NULL THEN ARRAY[ROW(
t.detection_date,
t.login_attempts,
t.friend_requests_sent,
t.posts_created,
t.flagged_reports
)::daily_detection_stats]
WHEN t.detection_date IS NOT NULL THEN y.daily_detection_stats || ARRAY[ROW(
t.detection_date,
t.login_attempts,
t.friend_requests_sent,
t.posts_created,
t.flagged_reports
)::daily_detection_stats]
ELSE y.daily_detection_stats
END AS daily_detection_stats,
CASE
WHEN y.account_id IS NULL THEN 'new'
WHEN t.account_id IS NULL THEN 'resolved'
WHEN t.detection_date IS NOT NULL AND y.fake_classification = 'resolved' THEN 'relabeled'
ELSE 'persisting'
END::fake_classification AS fake_classification,
CASE
WHEN t.detection_date IS NOT NULL THEN 0
ELSE y.days_since_last_detected + 1
END AS days_since_last_detected,
COALESCE(t.detection_date, y.current_detection_date + INTERVAL '1 day')::DATE AS current_detection_date
FROM today t
FULL OUTER JOIN yesterday y
ON t.account_id = y.account_id;