
How I got a 12x speed up in a 50 TB pipeline at Meta
Data Orchestration Challenges I Faced at Airbnb, Netflix & Facebook – Part III

In my time at Facebook, I worked on Notifications which, along with Messages and Ads, was the most volume-heavy pipeline in the company. Every ping you get from likes, tags, shares, comments, events is backed by mountains of notification data.
One of my most challenging assignments was owning the pipeline that deduplicated all notification events. This dataset drove downstream metrics like CTRs, conversions, and even machine learning signal quality.
This pipeline presented one big problem: it was slow. Very, very slow.
When I joined Facebook, the deduped notifications pipeline ran a giant Hive GROUP BY job once a day at UTC midnight which took 9.5 hours to complete. This latency issue represented a huge bottleneck for all downstream models in the Core Growth team.

This article is the story of how I brought 9.5-hour latency down to 45 minutes, and what it taught me about I/O, orchestration, and never trusting a “simple” DAG.
Here I’ll be covering the following:
Why streaming deduplication at scale failed
The hourly dedup job that exploded compute usage
A tree-based DAG design that saved the day
Key orchestration lessons from building a 300-step daily DAG
How this project got me promoted and why I almost gave up
If you want to learn more in depth about patterns like this, the DataExpert.io academy subscription has 200+ hours of content about system design, streaming pipelines, etc. The first 5 people can use code DEDUP for 30% off!
The Stakes: Notifications at Facebook Scale
The notif_events table contained every event tied to a notification:
Sent to your phone
Delivered to device
Clicked
Converted
Since one person might click the same notification multiple times, we had to dedup those. If we counted every click, we’d get click-through rates above 100%, which negatively impacted metric tracking and, worse, model training.
But the problem wasn’t logic. It was latency.
As I mentioned earlier, the dedup job ran once a day via Hive & took 9.5 hours to complete. My managers wanted me to reduce latency dramatically.
Approach 1: Stream It 😣
At first, my manager’s request was straightforward: ‘Let’s dedup in real-time’.
So, I tried. I built a Spark Streaming job that listened to notification events and tried to hold recent activity in-memory for comparison. But this approach was holding as much as 50+ terabytes in RAM to do real-time deduping.
This wasn’t feasible. The streaming job crumbled under memory pressure. I had to come up with a better solution.
Approach 2: Hourly Dedup + Merge 🤔
Our second approach was to dedup every hour. The idea was simple:
Dedup the current hour table and write it to a sorted, bucketed table (to minimize shuffle later with SMB join)
Merge with the previous hour table (a cumulative of all previous hours’ deduped data).
Output a deduped table up to the current hour.
The read and merge hourly deduped table to the previous hour can be implemented with this simple SQL pattern inside your DAG:
-- Hourly dedup logic
-- Remember this table is sorted and bucketed on user_id
INSERT OVERWRITE TABLE notif_deduped_hourly(ds='{{ ds }}', hour={{ current_hour}}, channel='{{ channel }}')
SELECT
notif_id,
user_id,
-- count the number of events of each type
-- a custom UDF that returned a MAP {"sent":1, "clicked":3}
COUNT_MAP(event_type) as event_map_count
FROM notif_events
WHERE event_hour = '{{ current_hour }}'
AND ds = '{{ ds }}'
AND channel = '{{ channel }}'
GROUP BY notif_id, user_id-- Then we merged the cumulative previous hours and the current hour with FULL OUTER JOIN
INSERT OVERWRITE TABLE notif_deduped_combined_hourly(ds='{{ ds }}', hour='{{ current_hour }}', channel='{{ channel }}')
WITH dedup_current_hour AS (
SELECT
*
FROM notif_deduped_hourly
WHERE hour = '{{ current_hour }}'
AND ds = '{{ ds }}'
AND channel = '{{ channel }}'
),
previous_hour AS (
SELECT
*
FROM notif_deduped_combined_hourly
WHERE hour = '{{ previous_hour }}'
AND ds = '{{ ds }}'
AND channel = '{{ channel }}'
)
SELECT
COALESCE(c.notif_id, p.notif_id) as notif_id,
COALESCE(c.user_id, p.user_id) as user_id,
-- udf that merges the keys of two maps
-- {"sent": 1, "clicked": 3} + {"clicked":4}
-- = {"sent":1, "clicked": 7}
COMBINE_MAPS(c.event_map_count, p.event_map_count) as event_map_count
FROM dedup_current_hour c FULL OUTER JOIN previous_hour p
ON c.notif_id = p.notif_id
-- This condition triggers the SMB join because both tables are sorted and bucketed on user_id
AND c.user_id = p.user_idThis approach actually worked. It lowered latency and produced correct results.
But it had a huge flaw: compute usage exploded. It used 15 times more compute than the original 9.5-hour GROUP BY job.
How was that possible? Quite straightforward:
Hour 1 processes 1 hour of data
Hour 2 reads and merges 2 hours
Hour 3 reads and merges 3 hours…
By hour 22, you find yourself reprocessing nearly the entire day’s data on every run.
It looked like this:
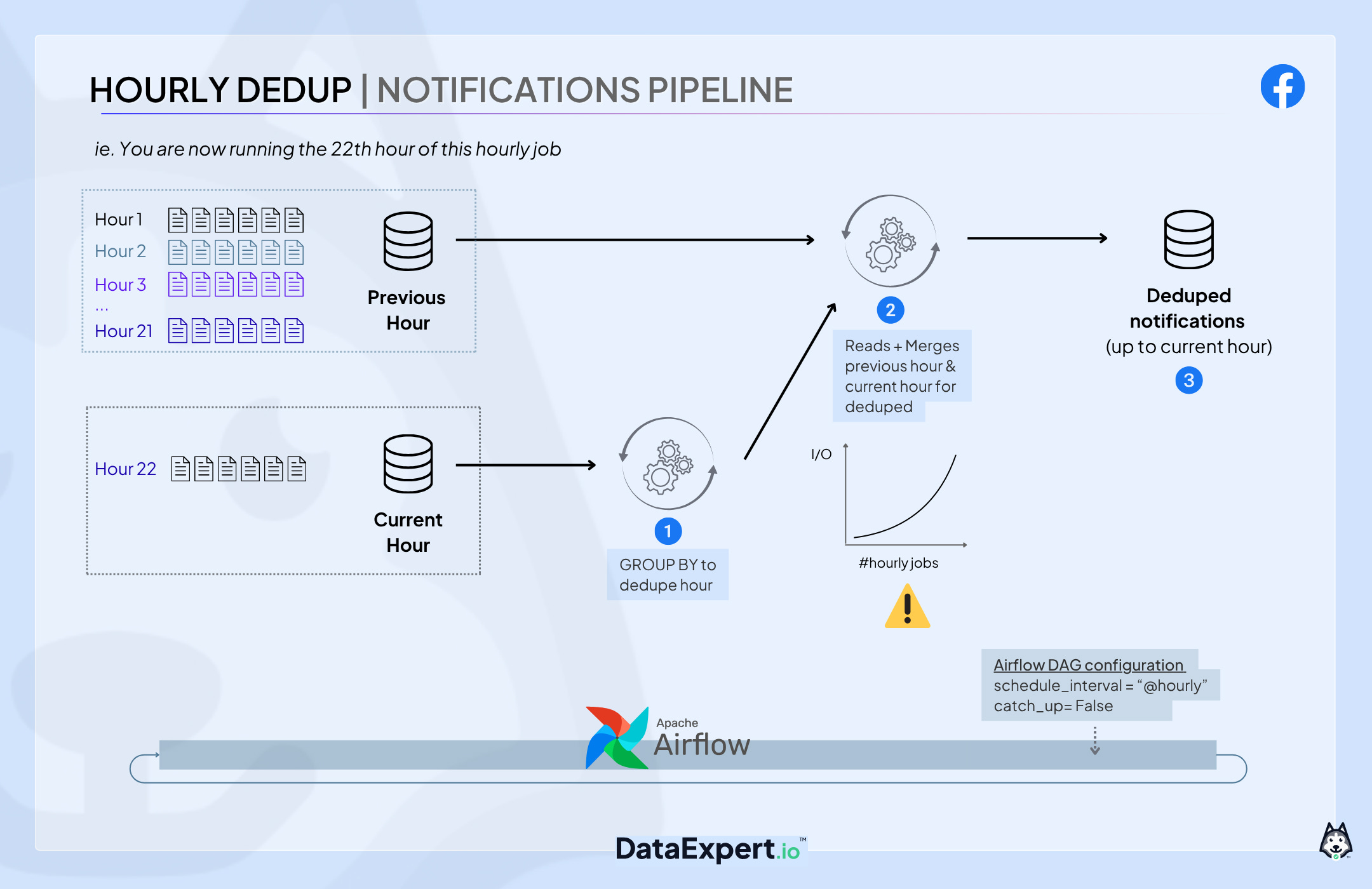
Once again, this solution was not sustainable, especially not for one of Facebook’s biggest datasets.
