
Junior data engineers build pipelines. Seniors build trust
Stop architecting. Start talking.


Hey, it’s Zach! This is part 3 in our series The Data Warehouse Setup No One Taught You. (Parts 1 and 2 here). Sahar has the special experience of being both a DE and SWE at Facebook, (as well as both in other companies) so he has a unique perspective on what makes DE special. Enjoy!
In 2026, Data Engineering is no longer about pipelines1. When your LLM writes SQL faster and better than you, when it debugs infra errors, when it can even write the logging code — we can’t pretend otherwise any longer. So what’s left?
Our job is to figure out what product (data) will find market fit with our customers (coworkers). And then build it.
And if they don’t use your stuff — that’s your fault, not theirs.
First, a story. Does it sound familiar?
A data engineer is tasked with fixing a swamp of google sheets, bespoke code, copies of prod databases, and random tables. They read books. They do research. They will Do It Right. They’re still setting things up by the time management loses faith in them. If they’re lucky, the project is cancelled. If they’re unlucky, they’re fired.
Variations of this story happen across the industry every day. They happen because we haven’t taught data engineers the big secret to the job – you may think you’re “just” a version of backend engineer. No. Data Engineers are product owners for data.
And in the AI age, it’s getting more and more obvious.
Our robot minions make the engineering grunt work easier2. That means everything else got more important: engineering strategy, and the people/product stuff.

Historically, the path from “here’s a data swamp no one uses or trusts, fix it” to “wow, thank you, here’s a promotion and the key to the city” has been tough. You gotta do 2/3 of one person’s job doing the human-relationship PMish stuff, and 2/3 of one person’s job doing the engineering. Plus another 2/3 of a person’s job responding to stochastic urgent requests from your team.
If the team doesn’t use your stuff — that’s your fault, not theirs.
Finally, there’s a way forward. The job has never been more fun.
Beyond the warehouse.
This is part 3 of our “The Data Warehouse Setup No One Taught You” series. So far, we’ve focused on a key set of tools – pipelines, the warehouse, and ingesting data in and out. Mostly expressed via SQL.
But of course, there’s a whole galaxy of other types of tools!3 Enough material that it’d take weeks of coursework just to cover it all. We’ll get into the most important of these in a future post in this series. (Part 4? Part 5?)
But that’s not the point right now. There’s an invisible universe of skills, consideration, and work that DEs do outside of tools. Outside of the “engineering” space. Things that involve judgement, office politics, product sense, communication, and a whole different type of thinking. That’s what most trainings, blog posts, and textbooks completely miss, and that’s what we’re covering today.
You are a data PM. PMs are strategic. You are strategic.
Like it or not, you’re part of the product and management team.
They will set goal metrics for the team – and if you don’t step in, they might set really stupid metrics that actively push everyone in the wrong direction. We all have a sacred duty to stop this from happening.
They make daily decisions such as cutting features, prioritizing between stability and iteration, resourcing teams, or whatever else. This is all based on their limited understanding of *your data*. Meanwhile, you’re constantly making data modeling decisions big and small. You need an intimate sense of your team’s product and users – what is, what could be, and what should be.
If their assumptions don’t match yours, the team/org/company/product will be in pain.4 If they don’t trust your data, nothing else matters. And if they don’t trust you, then they will not trust your data.

If all you do is respond to tickets and build artifacts, your career will suffer, your team will suffer, and you will have besmirched the honorable mission of our shared craft. Not to mention, a robot might take your job in a few months.
Your job is to help your customers (aka coworkers) make the right decisions.
Say you inherit a small warehouse setup with easily a year’s worth of obvious work ahead of you. You’re thrust into a situation with an existing data system that people don’t really trust.
“I’m going to roll up my sleeves and make more tables” is not the answer to a small warehouse.
“I’m going to write data quality checks and validate our flows” is not the complete answer to untrusted tables.
A data engineer’s job is to help their customers (coworkers) make the right decisions.
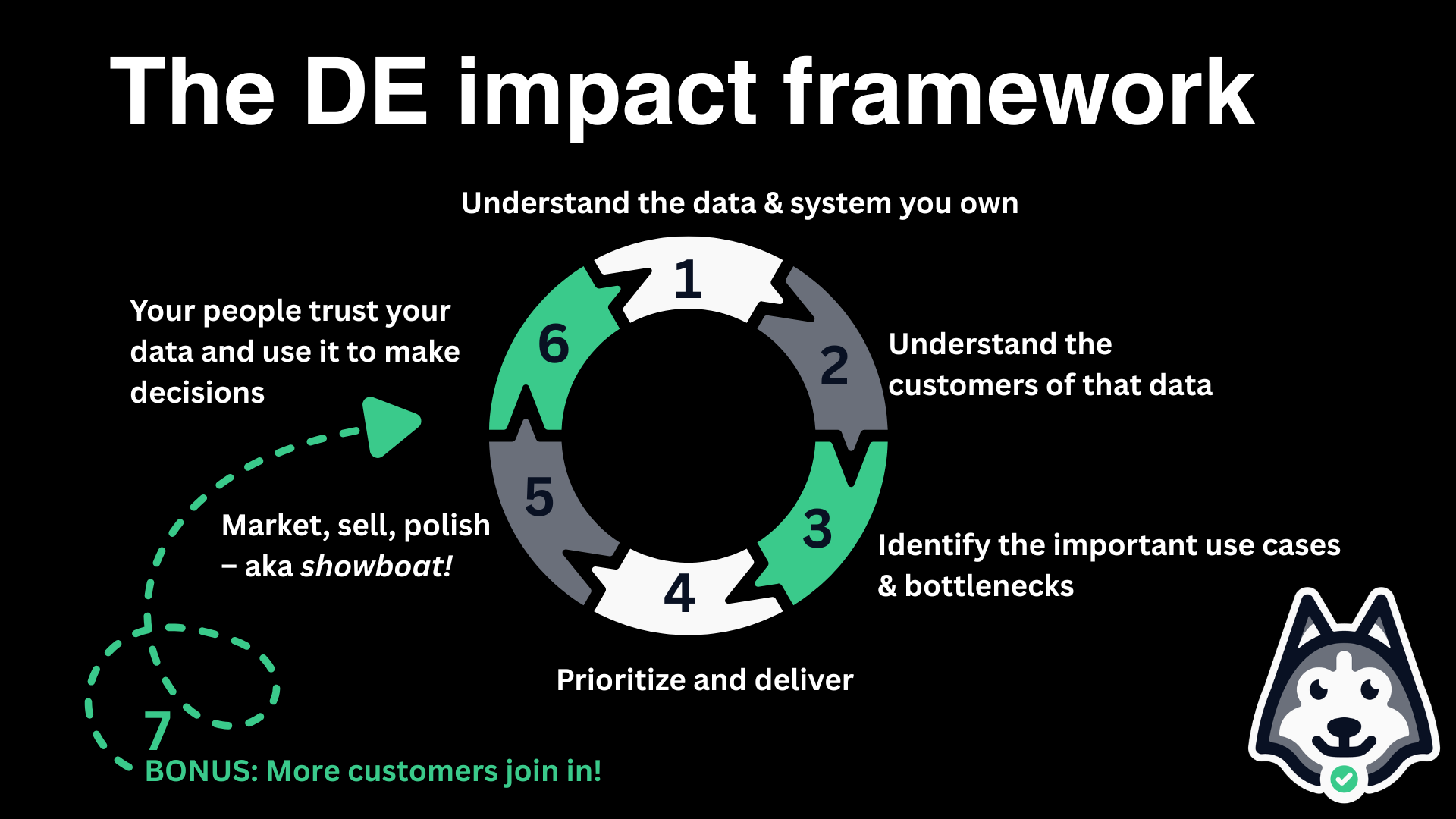
To do that:
Understand the data and data system under your purview
Understand the customers of that data and system
Identify the most important use cases, customers, bottlenecks, and improvements for the above
Prioritize and deliver
Market, sell, iterate, and even showboat …
So that customers are happier, trust the data and system, and use it to make key decisions
Bonus: so that more customers join in
Many data engineering manuals focus on #1 and #2. Maybe #4. Meh.
True senior data engineers know what to build, for whom. And then they make goddamn sure it’s not just used, but making an impact.
Showmanship is good, actually.
A story. I was three months into being a DE at Facebook and I was CONFUSED.
What was my job, exactly? What were the types of outputs that I was supposed to make? Tables and pipelines seemed to be part of it. Charts too. But no one really spelled it out.
I met my skip. He asked me what I was working on. I showed him a table I was painstakingly building and polishing. Our team was tracking how users (often abroad, often on android) were upgrading (or not) their version of the app. The table tracked each user/app/device tuple per day, so we could both analyze and instrument metrics around app upgrades.
He told me: “you think you’re making a table for your team. That’s fine. But actually what you’re making is a table that’s useful for the entire company. Rename it to something more general and tell people about it.”
I did it. If I recall correctly my blog post was titled something like “One Weird Trick for Much Better Growth Statistics”. It was my first little viral hit inside the company. Years later I’d still get calls from coworkers I never met, telling me how the table was core to their work and asking about the finer details.
The difference between a table that only three people in my team cared about and the viral hit that materially helped the company5 was just … pizzazz? (Plus a bit of insight)
To trust your data, they need to trust you
What I learned from the most successful DE I ever met
The data engineer I’ve seen reach the highest pinnacle of career success, the one who has so much power and influence that they’re known to power players in DC – I knew him way back when we were both IC’s at Facebook. Let’s call him Moriarty.
I’ve thought a fair bit about how he pulled it off. Moriarty had two key moves. The first was more minor, and mildly technical6. But the other key move was, in retrospect, killer.
Moriarty never let a question go unanswered for more than a few minutes. I thought maturity meant blocking off time to focus and batching my responses to pings. He did the opposite. He sacrificed everything on the altar of being maximally available, helpful, and low-latency to key members of his team.
While I thought my job was making data pipelines (“it’d be rude to query them and step on the toes of data scientists”), he made sure to fluently answer any data or analytics question within minutes. Infra, analysis, whatever. And if it took more than a few minutes, respond with an ETA.
Honestly, I wish I had followed his lead.
Yes, your data needs to be trustworthy, but that’s different than being trusted.
What does trust mean? Does it mean timely numbers, metrics that can be defended, or numbers that match their numbers? Or simply that you’re pingable and reliable?
It depends on your workplace, but some things seem universal.
Let’s go back to the data swamp. Imagine you’re trying to disentangle a system that people simply don’t have faith in.
To trust you, they need to trust your priorities
In your company/org/team, what do your customers actually pay attention to? What do they use as the numbers they actually refer to again and again?
Often, it’d be a surface that you don’t actually control. I’ve seen it be an automated daily email. I’ve seen it be a Google Sheet. I’ve even seen it as an Excel doc that someone compiles each day and emails around.
That’s the thin pillar of truth that the company brass are holding on to.
If you threaten that pillar (even in favor of your shiny new solution that’s better for XYZ reasons), they will react with overwhelming force.
Here’s the mantra: The surface they obsess about, you obsess about.
There’s an engineering lens that junior DEs often have. “This is a jank system”, they might say. “Why don’t we move this process7 to our actual data infra? It’s technically superior and easier and automatable in all these good ways”. BEWARE! If you try to blow it up and tell them to use your dashboard instead, you are asking for trouble!8

It’s better to use a product lens. Here’s what that might look like:
In this example, our customers are the C-suite. They like surface X (let’s say a Google sheet). Your job is not just to understand why they like the metrics/charts/numbers on that sheet, but to get to a place where they are sure that you understand why. Then have a gentle, iterative, plan to upgrade that surface. Maybe it’s piping in better numbers. Maybe it’s doing some caching work in the backend to get the sheet to load faster or be redundant.
Didn’t think your job involved making DQ checks for a Salesforce export? At the most senior levels, your job is to build trust with the people who matter so that they give you the go-ahead to do the bigger stuff.
The customer is not always right.
None of this means “only do what my coworkers want”, or “the job is just being a fancy analyst, no engineering required”.
The point of credibility is to spend it.
To argue for better goal metrics for your team
To replace bad numbers with better ones
To get support for the infra you need to build
To get buy-in on investing in your data model and architecture
To do what you do best
Prioritization: aka how I stopped worrying and learned to avoid overengineering.
It’s all about prioritization. It’s about asking WHY.
Here’s who might matter:
The PM, EM, or other leads on your product team (if you’re in a product team)
The c-suite, VPs, executives, founders (if you’re at the right kind of company)
Finance!
SWEs, Ops teams, and others who are day-to-day consumers of your product
The point of credibility is to spend it.
And here’s what might matter, in roughly descending order, depending on your office culture:
Making the company more money
Moving impact metrics upwards
Making metrics to track impact
Helping others to look good / make decisions / do their job
Avoiding losing the company money
…. (big gap here)
…
… (yep, still a gap)
…The aesthetic beauty of your code, system, setup, etc
A story about what matters
I was once young and foolish. I was working at a series B startup, and I had Plans. We were going to make a data warehouse. We were going to use Spark, the new hotness. I spent a month laying out every table we would need.
Reader, I never built those tables. We didn’t need Spark.
The thing I actually did, the thing actually worth putting on my resume, was just this: spending a few days going through the janky, messy, weird data in the prod replica database. Dumping it. Aggregating it via raw python. Manually finding the business metrics most useful for our pitch deck for getting to series C.
Thanks in part to me, we got that series C. It had nothing to do with big data, machine learning, causal inference, whatever. Just counting, averaging, and understanding metrics. Python scripts. That’s what we actually needed.
Whatever your job (engineer? lawyer? executive chef? marine biologist?) – you gotta know who your actual customers are. What they need from you. And deliver it.
Often, what they need might be:
Analysis now rather than a table that makes analysis easier next week
Prove that you can match previous (bad) numbers exactly before you show your new better numbers and account for why they’re different
A straight, raw arithmetic answer with 1 minute latency during a meeting vs a nuanced margin-of-error answer after it’s over
Maybe the key is to have lots of tables, but each can be less trusted. Or vice versa. Or maybe it’s about chart latency. Or something else. Depends on the role!
Now, I’m not saying deliver what they ask for. We have to figure out what they actually need. It’s hard to put it into special frameworks or charts. It’s wisdom. It comes from experience.
But that’s the job.
DataExpert.io and Adal are launching a free vibe coding hackathon on July 4th and 5th! The winners of this hackathon will get into DataExpert’s next Databricks bootcamp for free! ($3000 value). You can join here
Thanks for reading. You can always reach me here.
Yours truly, Sahar Massachi.
(Was it ever?)
Root Cause Analysis, SQL Writing, DQ checks, debugging infra problems, log writing, and more. Plus some things get a lot easier – unstructured data, semantic (vector) storage, prototyping. Perhaps all this could be the subject of a future post?
Data quality, streaming, alerting, business intelligence (charting), vector storage, sending warehouse data back to prod, dealing with unstructured data. Dashboards, streaming logs (into dashes?), data locality, namespaces. Infrastructure setup and monitoring, ingesting SaaS datasets. And so much more.
It may be that in small pockets of work, there are “pure” data engineers who think they’re insulated from petty concerns like “product teams”. But I bet you there will be people in positions of power making decisions based on their work, and those decisions are ripe for miscalculation based on flawed assumptions, caveats, etc. If you redefine “product” to include things like “our internal a/b testing tool” or “our infra service”, then it’s product teams all the way down.
And set my career trajectory!
The company was rolling out a new query engine – Presto. Moriarty became the master of Presto. He made friends with the engineers writing it. He figured out its tricks. He was using it early, often, effectively, months before everyone else.
A process, mind you, set up by non-technical people. (gasp!)
At the very least, better be sure that the numbers perfectly match (yes, match. If you have new, better numbers, you can put them on the sidebar or something). But honestly – just don’t.
Brilliant article. Especially the topic about trust. These nuances are in no training available. I think I should create those trainings with all kinds of timeless methods.