
The 2025 AI + Data Engineering Roadmap

Getting a data engineering job is complicated. After the crowd of people screaming “LEARN PYTHON AND SQL,” you’ll still find yourself lost in a sea of technologies like Spark, Flink, Iceberg, BigQuery, and now even AI-driven platforms.
Knowing where to start and how to get a handle on this requires some guidance. This newsletter is going to unveil the steps needed to break into data engineering in 2025 and how AI fits into the picture.
A lot of people still think that after you’ve done a magical number of Leetcode problems, a job falls into your lap. That’s almost never the case!
To get a job in 2025, you’ll need the following things:
Demonstrable skills with:
SQL and Python
Distributed compute (Snowflake, Spark, BigQuery, DuckDB)
Orchestration knowledge (Airflow, Mage, or Databricks workflows)
Data modeling and data quality
AI/data integrations (vector databases, embeddings, RAG pipelines)
An opportunity to demonstrate those skills via a portfolio project
A personal brand that radiates above the noise both on LinkedIn and in interviews
Let’s dig into each of these areas and see how you can fast-track your way to success!
Sponsorship

Tinybird helps companies like Vercel and Framer transform massive streams of real-time data into instant insights and real-time user experiences.
They built a free course on real-time data designed for data engineers who want to master the basics and build amazing data products.
Learning SQL
Avoiding SQL is the same as avoiding a job in data engineering. This is the most fundamental language you need to know.
There are many resources out there to learn it! The ones I recommend are:
Key things you should know in this bucket are:
The basics
JOINs
INNER, LEFT, FULL OUTER
Remember you should almost never use RIGHT JOIN
Aggregations with GROUP BY
Know the differences between COUNT and COUNT(DISTINCT)
Remember that COUNT(DISTINCT) is much slower in distributed environments like Spark
Know how to use aggregation functions with CASE WHEN statements
example: COUNT(CASE WHEN status = ‘expired’ THEN order_id END) this counts the number of expired orders
Know about cardinality reduction and bucketing your dimensions
example:
SELECT CASE WHEN age > 30 THEN ‘old’ ELSE ‘young’ END as age_bucket, COUNT(1) FROM users GROUP BY 1
You’ll see in this query, we take a high cardinality dimension like age and make it a lower cardinality (just two values “old” and “young”)
Common Table Expressions vs Subquery vs View vs Temp Table (a great YouTube video here)
The key things here are:
You should very rarely be using subquery (it hurts readability of pipelines)
You should use temp table if you need to reuse some logic since Temp Table gets materialized and will improve the performance of your pipeline
You should use View when you need to store logic for longer than the duration of the pipeline execution
In all other cases, you should use common table expressions to improve readability!
Understand how SQL works in distributed environments
Know what keywords trigger shuffle
JOIN, GROUP BY, ORDER BY
Know what keywords are extremely scalable (this means they’re executed entirely on the map-side)
SELECT, FROM, WHERE, LIMIT
Know window functions thoroughly (great YouTube video here)
The basics
RANK() OVER (PARTITION BY <partition> ORDER BY <order by> ROWS BETWEEN <preceding> PRECEDING AND <following rows>)You have the function (e.g. RANK, SUM, etc).
You have PARTITION BY this divides the window up. Maybe you want to do window functions per department or country?
You have ORDER BY this determines the sorting of the window
You have the ROWS BETWEEN clause to determine how many rows you should include in your window. If you don’t specify this, it defaults to ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. So the default is the “cumulative” row definition.
Understand RANK vs DENSE_RANK vs ROW_NUMBER(a quick two minute YouTube video about this)
Key things:
When there is no tie in your ORDER BY clause, these functions are identical
When there are ties,
RANK skips values (e.g. a tie for 1st place means the next place is third)
DENSE_RANK does not skip values (e.g. a tie for 1st place means the next place is second)
ROW_NUMBER guarantees unique values with no ties (a tie for first place means one of them will get second place, this is based on the natural ordering of the data)
Understand how to do “rolling” calculations
Rolling average and sum by department is a common interview question. You can solve it with a query like this:
SELECT revenue_date, SUM(revenue) OVER (PARTITION BY department ORDER BY revenue_date ROWS BETWEEN 30 PRECEDING AND CURRENT ROW) as thirty_day_rolling_revenue FROM daily_salesYou’ll see we split the window by department, then we look at the rolling 30 day period for each day and sum it up. You need to be careful here and ensure that there is data (even if it’s zero) for each date otherwise you’ll calculations will be wrong!
Know about the differences between INSERT INTO, INSERT OVERWRITE and MERGE
INSERT INTO just copies the data from the result query into the table. THIS IS PRONE TO DUPLICATES! If you’re using INSERT INTO, it should always be coupled with either TRUNCATE or a DELETE statement!
INSERT OVERWRITE is nice because it copies the data and replaces whatever existing data is in that partition. This is the most common one they use in big tech!
MERGE is nice because it looks at the existing data and copies only the rows that are updated and/or deletes the rows that aren’t in the incoming data. The only minus of MERGE is the comparisons it needs to do to accomplish this can be very slow for large data sets!
What’s new in 2025?
AI copilots like Databricks Genie and Snowflake Cortex will happily write SQL for you. But interviewers now test whether you can verify, debug, and optimize AI-generated SQL.
Understanding how SQL runs in distributed environments (shuffle, partitioning, scalability) is still your edge over someone blindly trusting a copilot.

Learning Python (and AI Integration)
SQL is great and can accomplish a lot in data engineering. There are limitations to it though. To overcome these limitations you need a more complete language like Python.
Here are the concepts you need to learn:
Data types and data structures
Basics
strings, integers, decimals, booleans
complex
lists (or arrays), dictionaries, stacks and queues
Other data structures you probably don’t need to learn (although these might show up in interviews which sucks!)
heaps, trees, graphs, self-balancing trees, tries
Algorithms
Basics
Loops, linear search, binary search
Big O Notation
You should be able to write down both the space and time complexity of algorithms
Algorithms you probably don’t need to know (although these might show up in interviews which sucks!)
Dijkstra's algorithm, dynamic programming, greedy algorithms
Using Python as an orchestrator
One of the most common use cases for Python in data engineering is to construct Airflow DAGs
Using Python to interact with REST APIs
A common data source for data engineers is REST data. Learn about GET, POST, PUT request in Python. The requests package in Python is great for this!
Know how to test your code with pytest (in Python) or JUnit (in Scala)
There’s a really solid library called Chispa that works well with pytest for testing your PySpark jobs you should check out!
New in 2025:
Python is now the glue between data engineering and AI. You’ll need to know:
Calling LLM APIs (OpenAI, Anthropic, open-source models)
Generating and storing embeddings
Working with vector databases (Pinecone, Milvus, Weaviate, pgvector)
Building lightweight RAG (Retrieval-Augmented Generation) pipelines
Writing “AI validators” — Python jobs that use an LLM to check data quality or generate documentation
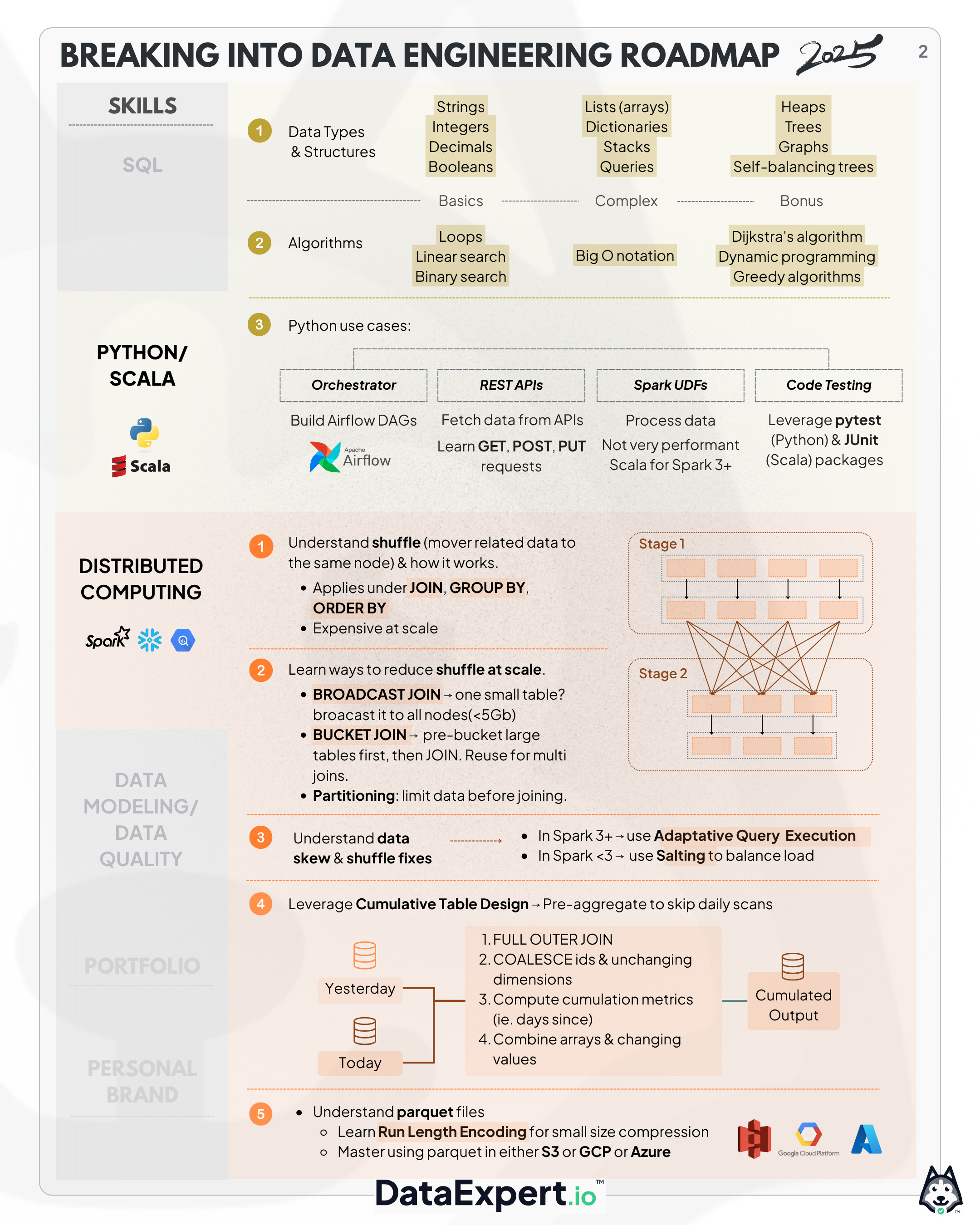
Learning Distributed Compute (either Spark, BigQuery or Snowflake)
Back in the late 2000s, Hadoop was born and so was the notion of distributed compute. This means that instead of having one fancy computer process all your data you have a team of computers each process a small chunk!
This concept unlocks the possibility of computing vast amounts of data in a small amount of time by leveraging teamwork! But this does not come without complexity!
Here are some things to consider:
Shuffle
If we are using teamwork, we need to guarantee certain data is on a certain machine (like if we are counting how many messages each user has received). The team accomplishes this guarantee by passing all of your data to one machine via shuffle (example in the diagram below). We only HAVE to do this when we do GROUP BY, JOIN, or ORDER BY. (a quick 2 minute video about how I managed this at petabyte scale at Netflix)
Shuffling isn’t a bad thing remember! It actually is really good because it makes distributed compute mostly the same as single node compute! The only time it gets in the way of things is at very large scale!
Things you should consider to reduce shuffling at very large scale
Broadcast JOIN
If one side of your JOIN is small (< 5 GBs), you can “broadcast” the entire data set to your executors. This allows you to do the join without shuffle which is much faster
Bucket JOIN
If both sides of your JOIN are large, you can bucket them first and then do the join, this allows. Remember you’ll still have to shuffle the data once to bucket it, but if you’re doing multiple JOIN with this data set it will be worth it!
Partitioning your data set
Sometimes you’re just trying to JOIN too much data because you should JOIN one day of data not multiple. Think about how you could do your JOIN with less data
Leverage cumulative table design
Sometimes you’ll be asked to aggregate multiple days of data for things like “monthly active users.” Instead of scanning thirty days of data, leverage cumulative table design to dramatically improve your pipeline’s performance!
Shuffle can have problems too! What if one team member gets a lot more data than the rest? This is called skew and happens rather frequently! There are a few options here:
In Spark 3+, you can enable adaptive execution. This solves the problem very quickly and I love Databricks for adding this feature!
In Spark <3, you can salt the JOIN or GROUP BY. Salting allows you to leverage random numbers so you get a more even distribution of your workload among your team members!
Output data
Most often when you’re using Spark, you’re going to be writing Parquet files to S3 or GCP or Azure. Parquet files have some interesting properties that allow for dramatic file size reduction if you use them right. (an in depth YouTube video about this).
The key property of parquet files that you need to know about is a thing called run length encoding compression. I shrunk pricing and availability datasets at Airbnb by over 90% by leveraging this technique!
If you’re using Snowflake or BigQuery, they use their own proprietary format that I know less about. So find another newsletter for that! Maybe Seattle Data Guy’s?
What’s new in 2025?
AI workloads run on your data stack (i.e. Shift Left)
Embedding generation at scale (GPU clusters with Spark or Ray)
Hybrid query engines that support both structured tables + vector search
Streaming inference pipelines with Kafka + Flink
Data Modeling and Data Quality
Data engineering is ultimately about delivering usable, correct, privacy-compliant data.
Here are the ways you can assess data quality:
Data should be correct
You should check for duplicates, NULLs, proper formatting. Also checking that there is the right number of rows in the data set!
Data should be usable and efficient
This means it should have proper documentation and good column names. The query patterns should also allow for fast answers to questions! Answers shouldn’t give Jeff Bezos millions of dollars either!
Data should be privacy-compliant
An often overlooked part of the puzzle. You shouldn’t be hurting user privacy to make your analytics better!
So how do you achieve this output data set nirvana dream? It has multiple parts!
Correctness should be handled in a few ways
The first pass should be via validation from a data analyst. This a part of the powerful MIDAS process at Airbnb that you should check out!
After that, you should build in automated data quality checks into your pipeline with something like Great Expectations. Remember to follow the write-audit-publish pattern here so you don’t publish bad data into production that doesn’t pass data quality checks!
Usability and efficiency are handled with a few things
Documentation should be a big part of the process. Spec building and stakeholder sign-off should happen BEFORE you start building your pipeline. This will prevent a lot of redoing and undoing of work!
Leveraging efficient practices for your data lake:
Manage your Apache Iceberg snapshots for time-traveling and disaster recovery
Set good retention policies on your data so you don’t have a huge cloud bill for data you do not use!
Data modeling is going to be the other big piece of this puzzle
There are a few camps here:
Relational data modeling
This type prioritizes data deduplication at the cost of more complex queries. Think of this as prioritizing storage at the cost of compute.
Dimensional (or Kimball) data modeling
This denormalizes the data into facts and dimensions which prioritizes larger queries but duplicates data a bit. Think of this as trying to balance the costs of storage and compute.
One Big Table
This denormalizes the data even more where the facts and dimensions are in one table. You duplicate data more but you get extremely efficient queries from it. Think of this as prioritizing compute at the cost of storage.
I wrote a long-form article detailing the differences and when to pick which one here. If you prefer video format you can find it here
Privacy compliant data sets
Be mindful where you have personally identifiable information in your data sets and don’t hold onto that longer than you need.
Remember that anything that can bring you back to a user is personally identifiable!
Anonymizing the data so you can hold onto it longer is a great strategy that balances user privacy and long-term analytical capabilities
New in 2025:
AI-assisted quality checks. Tools now let you point LLMs at logs or query results to spot anomalies.
Semantic modeling. Using embeddings to cluster or enrich tables with “semantic meaning.”
Privacy in AI. You must ensure embeddings don’t leak personally identifiable information. Vector search can accidentally memorize sensitive data if you’re careless.


Building a Portfolio Project
This is where you separate yourself from the pack.
You should pick a project that:
You care about deeply. I was obsessed about Magic the Gathering and that was what allowed me to keep working on that project even though I wasn’t getting paid
You can work on it for 3 months at 5-10 hours per week. A portfolio piece shouldn’t be easy to create. If it was easy to create, everybody would do it and then you wouldn’t stand out!
You build a piece that has a frontend! Another portfolio piece I build was HaloGods.com a website I built that allowed me to reach 20th in the world in Halo 5 back in 2016. Without a frontend, your data pipelines are a little bit harder to show off. This is why learning a skill like Tableau or Power BI can be a really solid way to make your portfolio shine even if those aren’t skills you end up using on the job!
You implement the following things in your portfolio
A comprehensive documentation that details all the inputs and output data sets, the data quality checks, how often the pipeline runs, etc.
You have a pipeline running in production. Using something like Databricks Free Edition would be a great place to get started!
You leverage hot technologies like Spark, Snowflake, Vector Databases, Iceberg, and/or Delta Lake.
If you want to stand out, you build a JavaScript front end like I did with HaloGods and you’ll find yourself landing jobs in big tech even though you didn’t go to Stanford, MIT or IIT.
In 2025, you’ll want something that shows both data pipelines and AI integration. Remember you can use AI to get the boilerplate and you add your own details to get started!
Ideas:
E-commerce pipeline → warehouse model → AI recommendation system
Ingesting data from Polygon.io → stock market model → AI stock picker system
YouTube transcript ingestion → Iceberg tables → semantic search UI with RAG
Automated data quality alerts using GPT validators
Remember, you might have to pay a tiny bit of money to build these projects. But it will be worth it over the long run!
Building a Personal Brand
So you have the skills and the sexy portfolio project. Now all you got to do is not mess up the job interview and you’ll be golden.
Here are some things you should do to get there:
Build relationships on LinkedIn
You should be building relationships with
Hiring managers and recruiters
Peers
You should start talking with people BEFORE you ask for a referral and start building up friendships and your network.
If you need a referral, it would be better to send out DMs to people and ask them what the job is like. Leading with questions instead of tasks will have a much higher hit rate!
Also remember that this DM game is a low percentage play. If you send out 20 DMs, 1 or 2 might respond, especially if you’re early in your career. Finding creators and employees that are near your same level will help increase that hit rate!
Create your own content and talk about your learning journey. You’d be surprised how effective this is at landing you opportunities you didn’t even think were possible. For example, I made $600k from LinkedIn in 7 months after quitting my job! Content creation and branding are a very powerful combo that can change your life!
Nowadays with AI, you can use AI aid in the content creation process! Just remember to remove the ugly emojis, em dashes, and
Interview like a person, not a robot
When you go into the interview make sure you have:
Researched the people who are interviewing you. You should know
How long they’ve worked for the company
What they do for the company
Asked the recruiter a lot of detailed questions about the role
What technologies will I be using
How many people will be on my team
What is the culture like
During the interview you should radiate
positivity, enthusiasm and excitement for the role
competence and calm when asked questions
curiosity to engage in stupid interview questions and curiosity about the role and what you’ll be doing by asking good follow up questions
Demonstrate technical skills during the interview
Conclusion
Getting into data engineering in 2025 is still hard. The job market is competitive. But the best engineers and the best startups are built in times like this.
The difference now? AI is part of the job. You don’t need to be an AI researcher, but you do need to know how to integrate AI responsibly into your pipelines.
Follow this roadmap and you’ll be much closer to landing the data engineering role of your dreams.
I am launching a new AI Engineering Boot camp starting on October 20th where we are covering all the new AI topics necessary to be a good AI-enabled data engineer. You can get 30% off with code AIROADMAP here.
What else do you think is critical to learn in data engineering to excel in the field? Anything I missed here that you would add? Please share this with your friends and on LinkedIn if you found it useful!
Very insightful. The hard but rewarding part is overcoming procrastination and working on that portfolio project even when no one assigns it to you, and there is no immediate financial gain. But it truly pays off and boosts your confidence once it’s done
Great blog. Happy to see that you still keep Scala in your courses. If we wanted to touch OSS projects, or work with legacy projects, one needs to work with Scala. Would be interested to know what could be the take if any newer data platforms are considering Scala at all ?