
Databricks is no longer about tuning knobs
Business is all that matters

For years, Databricks positioned itself as the true home of serious data engineers. They offer Spark jobs, distributed systems, lakehouse architecture, the works. But that’s old Databricks.
But if you zoom out and look at the product direction over the last few years, a much different pattern emerges.

Here are three observations that show that Databricks has moved on from data engineers:
Physical Data Modeling is a skill that doesn’t matter (a quick YouTube video on WHY IT STILL DOES)
Databricks spent over a $1B on Tabular to slow its progress
Most businesses don’t want to learn data. They want to get value from it
1. Physical data modeling is a skill that no longer matters (according to Databricks)
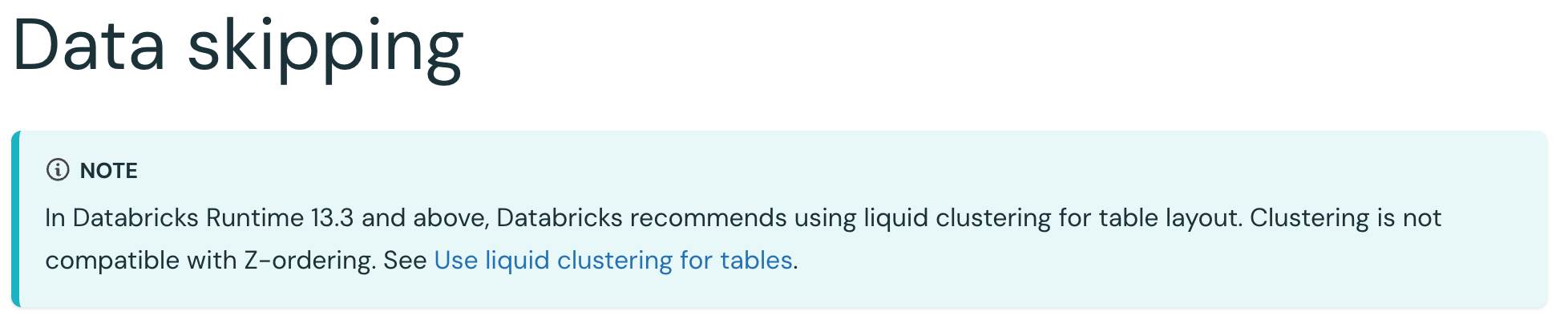
Since the early 2010s, Data engineers have been physically modeling data via partitioning, sorting, bucketing, etc.
These types of physical data modeling techniques created things like zorder, SMB join (a join without shuffle), file compactions, and data index skipping.
Now, Databricks says “don’t partition or sort or bucket” your tables. Your expertise is no longer needed here.
Instead of partitioning or bucketing, you now have “liquid clustering.”
Instead of file compaction and table layouts, you now have “predictive optimization.”
Databricks has steadily abstracted away the entire physical data modeling skillset. This is fantastic for analysts.
They don’t want to think about small files, metadata bloat, or clustering keys. They want queries to run fast and solve business problems even faster.
But engineers?
Engineers care about mechanics. File pruning behavior. Snapshot retention. Metadata growth. Table property tuning. Failure modes.
The philosophical shift is clear: reduce footguns by reducing access to the gun.
Once you upgrade beyond Databricks 13.3, you can retire your physical data modeling skills and put them in the trash.
2. Databricks spent $1B on Tabular to slow Iceberg’s progress
With open-source Iceberg, you get:
Deterministic file layout (You decide the sorting, the partitioning, and the bucketing)
Nearly two years after the acquisition, you can create managed Iceberg tables in Databricks. But you cannot optimize them. You cannot call file compaction. You cannot manage the snapshots. You cannot use hidden partitioning.
Databricks’ support of Iceberg is flawed.
It doesn’t support the hidden partitioning using things like days(event_time), year(event_time), etc
Managed Iceberg doesn’t allow you to do your own file compaction. You can do auto file compaction with liquid clustering only
To use managed Iceberg, predictive optimization HAS TO BE ENABLED.

Screenshot from Databricks AI assistant. If you don’t enable predictive optimization and give up control, you can’t use managed Iceberg.

All of this is saying, “We bought Tabular not to support the strengths of Iceberg.”
When Databricks deprecated the Tabular metastore, I migrated my 13,000 tables to Glue catalog instead of Unity Catalog because its offering was flawed, and I prefer to teach true physical data modeling, not “Databricks magic.”
Data engineers love determinism, explicit table layouts, visibility, and control.
Databricks now offers ease of use, unpredictable table layouts, opacity, and a lack of control.
Don’t get me wrong. This isn’t a bad thing for Databricks. The trade-off makes their product more available to less technical people, but it alienates experts who know what they’re doing.
3. Most businesses don’t actually want to learn data.
Data is seen as an impediment to business value. It’s raw, unrefined, and very easy to do wrong.
Also, data engineers are expensive, burn out quickly, and are increasingly automatable. The parts of the job that companies used to pay a premium for: writing boilerplate Spark jobs, tuning clusters, managing file layouts, optimizing joins. These are exactly the things AI can now scaffold in seconds.
What most companies actually want is not better data engineering.
They want:
Dashboards that load instantly
Models that work
Pipelines that don’t break
Costs that don’t spike unpredictably
Governance without reading a whitepaper
They don’t want to debate partitioning strategies.
They don’t want to argue Iceberg vs Delta.
They don’t want to tune shuffle partitions.
They want it to just work.
If you have:
Analysts writing transformations in SQL
AI generating pipeline code and tests
Databricks handling optimization (Liquid Clustering, Photon, Predictive Optimization)
Unity Catalog abstracting governance
You’ve effectively collapsed the traditional data engineering function into the platform.
That combination is extremely powerful — and usually cheaper than hiring a senior data engineer.
From an executive’s perspective, this is obvious:
Lower headcount
Faster iteration
Fewer specialized bottlenecks
Less infrastructure decision risk
This is the Snowflake playbook, and Databricks loves to follow their lead
The uncomfortable truth for data engineers is this: The market is rewarding abstraction, not control.
The companies growing fastest aren’t selling “deep control over distributed systems.”
They’re selling “you don’t have to think about it.”
And most businesses will choose that every time.
So what does this mean?
Databricks isn’t bad for data engineers. But teaching Databricks has become increasingly more boring.
When the answer to the question: “How to make my job more efficient?” is “Just let Databricks handle it.” It undermines the value of truly understanding how data works.
The pendulum is swinging in favor of analysts with these changes. The closer you are to the business, the more valuable you will become. Because Databricks is boldly telling you, “Your physical data modeling skills are no longer needed.”
I want to leave you with a few questions. Please comment on what you think:
With Snowflake and Databricks both leaning into “it just works” magic, where is the home for the data experts who actually know what they are doing?
How will we discover new physical data modeling techniques if all the control is ceded to Databricks?
So is trying to pivot into data engineering a lost cause at this point, with so many people actively trying to automate it out of existence? Hard to find any motivation to learn anything when it feels like the certain individuals are working hard to make sure nobody has a future.
Great article, Zach , really resonated.
But I wonder if this isn't just the natural evolution we've always seen. Research moved from books → online papers → Stack Overflow → now AI. Development went from text editors → notebooks → IDEs → now AI agents. Even navigation from paper maps → GPS → Google Maps predicting traffic before we hit it.
Each step removed friction. The goal stayed the same.
Maybe DE is going through the same shift. If we're not tuning knobs anymore, maybe the value just moves to better modeling, sharper system thinking, cost awareness, understanding what the business actually needs.
I'll be honest , I'm in the same boat. 10 years in, I sometimes wonder how relevant my core skills will be in a few years. But I still catch myself adding value in weird moments like connecting dots in meetings, making sense of messy conversations, asking the questions no one else thinks to ask.
Maybe the knobs change. The thinking doesn't.
Curious how you see it playing out.